1.导读
众所周知,gen是Stata中使用频率非常高的变量生成命令之一。诶,难道还有其他变量生成命令?是的,egen(extension of generate)作为gen的扩展,对gen命令进行了补充,帮助我们更好地使用变量生成功能。2.gen与egen的比较
我们将从语法出发,比较gen与egen的异同,看看egen是如何对gen进行扩展的。
gen的语法为:
generate [type] newvar[:lblname] =exp [if] [in] [,before(varname) |after(varname)]
egen的语法为:
egen [type] newvar = fcn(arguments) [if] [in] [, options]
相同点:
(1)gen和egen都是变量生成命令;
(2)变量类型[type]均为可选项,缺省时,gen和egen能够根据新生成的变量值自动判断并分配数据类型;
(3)两者都能选用[if]和[in]进行条件判断和范围选择;
(4)两者都可以使用by前缀(在某些情况下egen无法使用by分组功能)。
不同点:
(1)[:lblname]选项使gen可以在生成新变量的同时赋予其已定义的值标签,并且[, before(varname) |after(varname)]选项允许我们调整新变量的顺序;
(2)敲重点:使用gen生成的新变量,其变量值是由给定的表达式(exp)计算所得,表达式中可以使用Stata中的任意运算符(如,代数运算符”+” “-“ “*” “\”,逻辑运算符”>” “<” “|” “&” “!”等)和九大类函数;
(3)敲重点:egen只能使用专属的egen函数来为新变量计算变量值,如mean()、rank()等。值得注意的是,egen函数只能在egen命令下使用,不能用在gen的表达式中,egen命令也无法使用任何运算符或九大类函数来计算生成变量值;
(4)在使用gen命令时,_n和_N是我们常用的下标变量,用于表示行号和总观测值非常方便,但egen却无法使用。这是为什么呢?因为egen专属函数往往以某个变量或某一观测目标为参数,计算某个变量(一列)或观测目标(一行)的某种特征(比如均值,使用mean()),因此无需使用_n和_N。这也提示了egen生成的新变量值往往是一个常数(constant),当然也有egen专属函数的返回值不是常数,而gen生成的变量值则是一个变动值(running value)。
3.案例分析
下面,我们通过一个简单的例子来验证上述异同点。
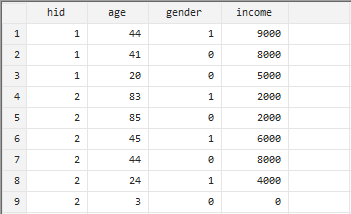
现有两个家庭:第一个家庭是一个三口之家,父亲、母亲、女儿的年龄分别是44、41、20岁;第二个家庭三代同堂,祖父祖母为83、85岁,父亲母亲为45、44岁,儿子24岁,孙女3岁。
插入input命令,把两个家庭的把相关数据写入stata数据集:
input hid age gender income1 44 1 90001 41 0 80001 20 0 50002 83 1 20002 85 0 20002 45 1 60002 44 0 80002 24 1 40002 3 0 0end
查看Stata数据集:
(1)生成一个新变量sex:使其等于gender并以“1 `男’ 0 `女’”的值标签显示。
label define sexlb 1 “男” 0 “女”gen sex:sexlb = gender
运行结果如下图所示,表明gen命令能够在创建新变量的同时赋予已定义的值标签,但egen没有该功能。

(2)生成个人id变量:为每个家庭成员编码,比如第一个家庭中父亲的编码为11,第二个家庭中祖父的编码为21。
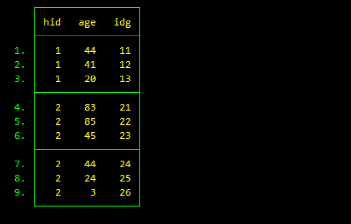
*尝试用gen生成:
bysort hid: gen idg = hid*10+_n
运行结果如下,各成员编码正确。
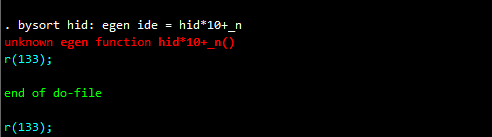
*尝试用egen生成:
bysort hid: egen ide = hid*10+_n
运行出现错误。显然,egen无法使用运算符,只能使用其专属的函数来计算生成变量值。
(3)生成AgeRank变量:以家庭为单位,对家庭成员按年龄升序排序;生成hsize变量:计算每个家庭的人口数。
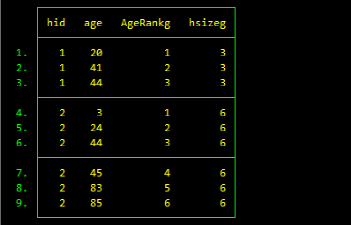
*使用gen生成:
bysort hid (age): gen AgeRankg = _n //使用bysort对hid分组并排序,(age)表示age不参与分组,仅参与家庭内部的排序。bysort hid: gen hsizeg = _N
运行结果如下图所示,第一个家庭为3人,第二个家庭为6人。
*使用egen生成:
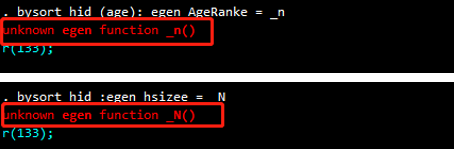
bysort hid (age): egen AgeRanke = _nbysort hid :egen hsizee = _N
运行出错,表明egen无法使用_n和_N。
(4)生成mean变量:计算每个家庭的平均年龄。
*使用gen创建新变量:
bysort hid: gen meang = mean(age)
运行出错,表示gen无法使用egen专属函数。
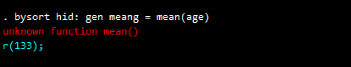
*使用egen创建新变量:
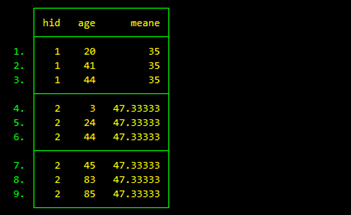
bysort hid: egen meane = mean(age)
运行结果如图所示,这表明egen的一些函数可以搭配by前缀使用。
(5)生成IncomeSum变量:计算两个家庭的总收入。
gen IncomeSumg = sum(income)egen IncomeSume = sum(income)
运行结果如下图所示。
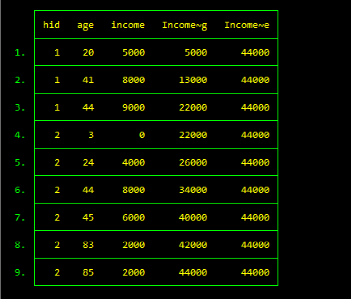
特别地,目前仅发现sum()函数能够同时被gen和egen使用。利用gen命令,使用sum()函数生成的IncomeSumg是列累积和,比如IncomeSumg[2]=income[1]+ income[2] ,是一个变动值(running value),而在egen命令下sum()返回的则是列总和,IncomeSume的每一个变量值都等于income变量值的总和(即44000=5000+8000+9000+0+4000+8000+6000+2000+2000),是一个常数(constant)。
实际上,sum()作为一个常规数学函数,并不属于egen专属函数,并且egen专属函数中的total()函数功能与sum()完全一致——返回列总和。这个矛盾我们目前尚无答案,读者朋友们如有合理的想法请在评论区告诉我们唷~4.结论
综合上述分析,我们能够得到启示:使用gen命令创建新变量是一种“相对”创建,比如,现要求生成一个新变量,个人年收入incomey:
gen incomey = income*1
这个命令的实质是,创建一个新变量incomey,使得:
incomey[1] = income[1]*12incomey[2] = imcome[2]*12…incomey[_N] = income[_N]*12
而egen的某些专属函数的参数往往是某一整行或某一整列,比如计算两个家庭的月收入均值,月收入的下四分位数:
egen meani = mean(income)egen pctile4 = pctile(income),p(25)
其中,income是作为收入总和(即44000)参与计算的,这与gen命令有显著的不同。
当然,egen还有许多其他专属函数,比如anycount()、anymatch()等使用“相对”创建方法的专属函数,也有rowfirst()、rowmax()等对每行进行匹配和判断的函数……总之,当你想创建一个以整行或整列的特征为结果或判断、匹配条件时就可以考虑使用egen命令啦。

